
ABSTRACT
This paper aims to develop a low-cost, high-performance and high-reliability computing system to process large-scale data using common data mining algorithms in the Internet of Things (IoT) computing environment. Considering the characteristics of IoT data processing, similar to mainstream high performance computing, we use a GPU (Graphics Processing Unit) cluster to achieve better IoT services. Firstly, we present an energy consumption calculation method (ECCM) based on WSNs. Then, using the CUDA (Compute Unified Device Architecture) Programming model, we propose a Two-level Parallel Optimization Model (TLPOM) which exploits reasonable resource planning and common compiler optimization techniques to obtain the best blocks and threads configuration considering the resource constraints of each node.
The key to this part is dynamic coupling Thread-Level Parallelism (TLP) and Instruction-Level Parallelism (ILP) to improve the performance of the algorithms without additional energy consumption. Finally, combining the ECCM and the TLPOM, we use the Reliable GPU Cluster Architecture (RGCA) to obtain a high-reliability computing system considering the nodes diversity, algorithm characteristics, etc. The results show that the performance of the algorithms significantly increased by 34.1%, 33.96% and 24.07% for Fermi, Kepler and Maxwell on average with TLPOM and the RGCA ensures that our IoT computing system provides low-cost and high-reliability services.
RELATED WORK
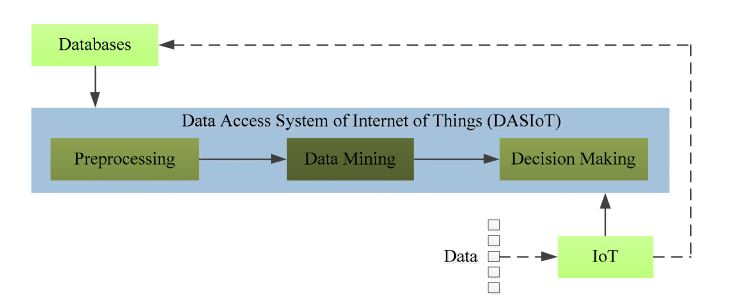
Figure 2. Basic structure of the DASIoT
With the development of the IoT, an increasing amount of large-scale data needs to bin the DASIoT. However, challenges concerning how to process the data and how to extract useful information have emerged in recent years. The problem we have to consider is that the data from IoT is usually too large and it is too difficult to process using the ways available today. As paper proposed, the bottleneck of IoT services will shift from Internet to data mining, transformation, etc.
Since the issue of processing massive data has been studied for years, it is not surprising that some classical but practical ways have been applied in IoT, such as random sampling, data condensation, and incremental learning. However, these methods only handle partial data instead of all the data, so all of these studies need a data preprocess in DASIoT, as shown in Fig. 2.
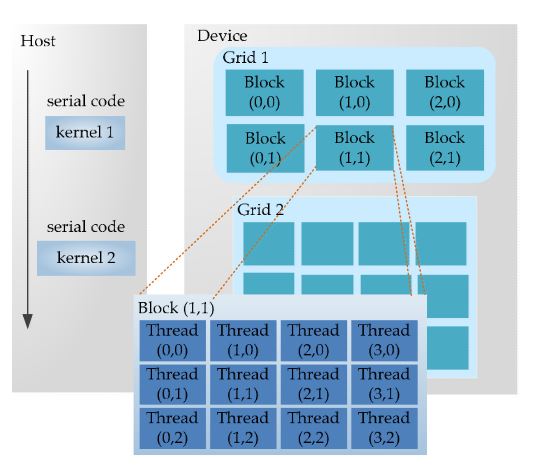
Figure 3. CUDA programming model
Once the kernel is determined, this part is handed over to the GPU. The parallel computing function running on the GPU is called the kernel. A kernel is just a part of a program, and it can be executed in parallel. As shown in Figure 3, a complete CUDA program consists of multiple device-end parallel kernels and the host-end serial processing steps. There are two-level parallel hierarchy in a kernel, and one is the blocks in the grid and another is the threads in the block. The two-tier parallel model is one of the most important innovations of CUDA, which is also the original source of inspiration for our performance optimization model.
Power Consumption Calculation Model
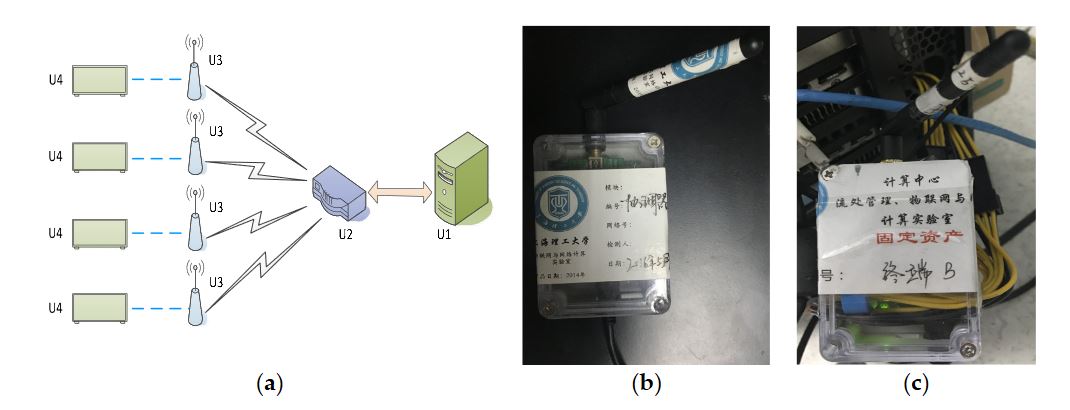
Figure 5. GPU energy consumption monitoring system
In Section 3.2, we discussed that the current is obtained from a homemade wireless sensor network, the power consumption monitoring system of the GPU cluster. As seen from Figure 5, it is composed of multiple components: a master monitor terminal U1, a Zigbee coordinator U2, multiple sensor nodes U3 and a U4b GPU cluster (including multiple GPU computing nodes). The system also contains multiple slave monitor terminals, but these are not shown in Figure 4. U3 contains a node controller and a Hall current sensor connected to the node controller and a Zigbee communication module.
Two-Level Parallelism Optimization Model
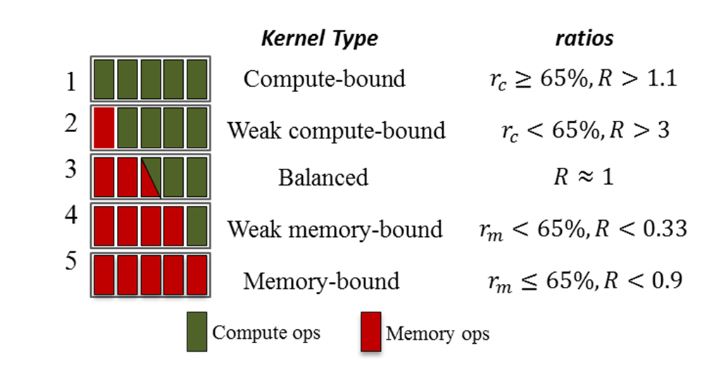
Figure 6. Kernel type categorization based on the resource utilization ratios. The critical values are empirically chosen
In terms of the above rules, if either of the ratios is more than 65% firstly, the kernel is likely limited by the metric. To better characterize kernel behavior, we break the kernels down into the five types, as shown in Figure 6, based on their resource utilization ratios: compute-bound, weak compute-bound, balanced, weak memory-bound and memory-bound.
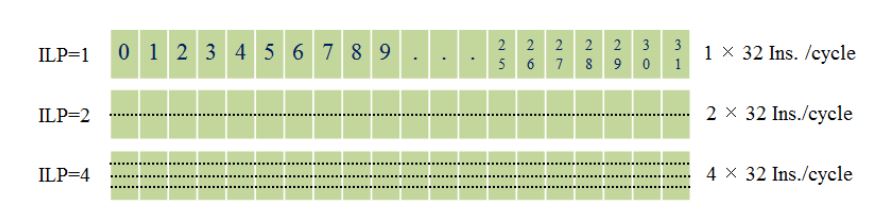
Figure 8. Intra-thread execution order simulation
With our TLPOM, we reduce long latency using much less warps per block, as shown in Figure 7b. It also follows a round-robin order, but it has more memory throughput than ILP0. When executing the same number of tasks, it is able to exploit less warps (threads) which own more instructions concurrently per thread. Hence, the long latency operations can be more effectively hidden with our model. The intra-thread execution behavior is simulated as shown in Figure 8, showing the different instructions which are issued when ILP is changed for each warp per clock.
Reliable GPU Cluster Architecture
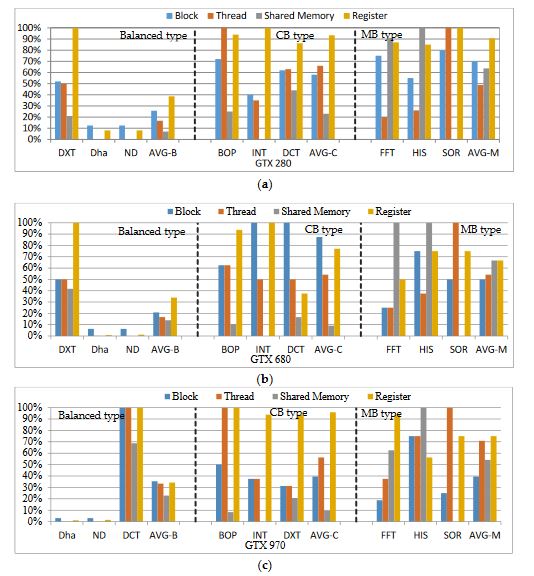
Figure 9. The resource utilization of different type kernels on different GPUs
In addition to quantifying a variety of resources in cluster, for different type kernels, we need to statistically analyze the resource usage of different nodes. This analysis can assist the reliability scheduling of our cluster. We quantify four kinds of primary resources, as shown in Figure 9. If any of the resource usage reaches its limit, no more blocks can be scheduled even though all the other resources are still available. Figure 9 presents the proportion of SM resources used by primary kernel/kernels (execution duration more than 70%) of each algorithm. In Figure 9, we statistically analyze nine programs from different experiment suites, including CUDA SDK, Rodinia3.1 and SHOC suite.
EVALUATION
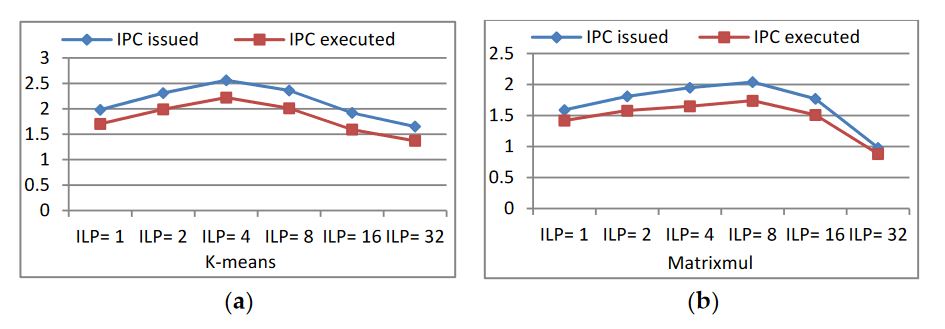
Figure 12. IPC issued and executed behaviors
With the changing of ILP (TLP is also changed), the issued IPC (the average number of issued instructions per cycle) and executed IPC (the average number of executed instructions per cycle) of the programs have corresponding changes. When the program has a higher issued IPC, more instructions can be issued per clock, so latency becomes short. A higher executed IPC indicates the more efficient usage of the available resources, and the programs have better performance. The maximum achievable target IPC for a kernel is dependent on the mixture of the instructions executed. From Figure 12, we know that k-means and Matrixmul can issue maximum instructions per clock when they have four and eight independent instructions in a single thread, respectively.
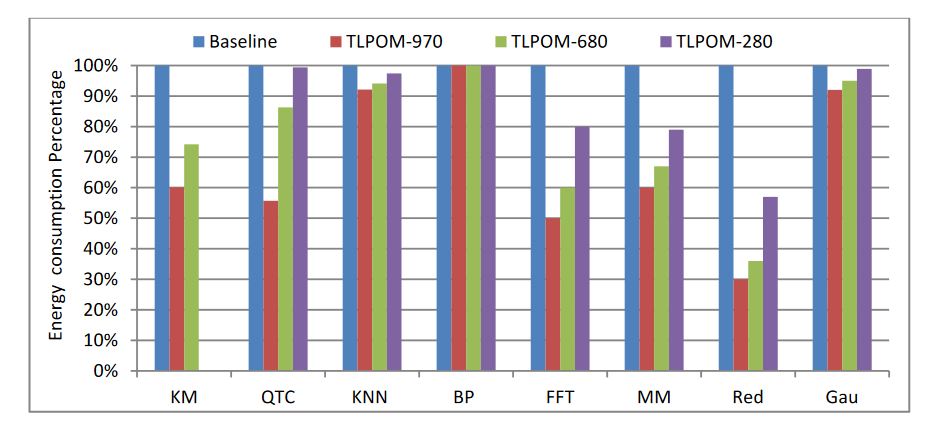
Figure 15. Energy consumption of data mining algorithms
The results are also normalized as in Figure 11, and the values of the baseline energy consumption of the three GPUs are different. The figure presents that the energy consumption of these algorithms is almost inversely proportional to their performance. Except for BPNN, all the others have different degrees of energy consumption decline, especially Matrixmul and Reduction. Why does the energy consumption of these algorithms reduce after adjusting the TLP and ILP? Because the TLPOM increases the operations/elements of a single thread to process and also increases the register files and the usage of other on-chip memory structures. Furthermore, it makes the data acquisition operation from the global memory drop significantly, reducing the refresh rate of the device memory and further lowering energy consumption.
CONCLUSIONS
The Data Access System for the Internet of Things (DASIoT), as a crucial part of the WSN, plays a decisive role in large-scale sensor data access and processing. To cope with the massive original access data in the IoT, one of the most important technologies is data mining, because it can convert the data collected by DASIoT into useful information and further provide a better service for the user. In this paper, our goal is to provide a low-cost, high-performance and high-reliability computing system for common data mining algorithms in IoT computing. Our optimization scheme is divided into three parts.
Firstly, we present an energy consumption calculation method (ECCM). Then, we provide a two-level parallel optimization model (TLPOM)-based CUDA programming and to improve the performance of these algorithms. Finally, in order to obtain a long-term, error-free runtime environment, we put forward a reliable GPU cluster architecture (RGCA) under limited resources. In the process of optimizing performance, we assign a different number of blocks/threads per grid/block to acquire the best launch configuration, and we also use common compiler optimization techniques, for example loop unrolling. On the basis of the performance improvements, we define the GPU cluster energy consumption calculation model by capturing the real-time current to calculate the energy consumption.
Then, with full consideration of the computational capacity, GPU resources and the characteristics of algorithms, we obtain a high-reliability computing system. Our experiments demonstrate the effectiveness of our optimization scheme. Further work will cover an extension of the proposed high-reliability computing system, and on this basis, we will study in-depth the reliability scheduling and fault tolerance scheme for IoT computing. During implementation, the fault detection and recovery mechanism will be added to the task execution. The fault nodes should be migrated and revisited to ensure the reliability of the system. Further work will also take into consideration the GPU computing cluster to undertake large-scale real-time data processing.
Source: University of Shanghai for Science and Technology
Authors: Yuling Fang | Qingkui Chen | Neal N. Xiong | Deyu Zhao | Jingjuan Wang
>> 200+ IoT Led Projects for Final Year Students
>> More Internet of Things (IoT) Diy Projects for Engineering Students
>> More Wireless Energy Projects for Engineering Students
>> More Wireless Projects Using Zigbee for Engineering Students