
ABSTRACT
With the emergence of the Internet of Things (IoT), a large number of physical objects in daily life have been aggressively connected to the Internet. As the number of objects connected to networks increases, the security systems face a critical challenge due to the global connectivity and accessibility of the IoT. However, it is difficult to adapt traditional security systems to the objects in the IoT, because of their limited computing power and memory size. In light of this, we present a lightweight security system that uses a novel malicious pattern-matching engine. We limit the memory usage of the proposed system in order to make it work on resource-constrained devices.
To mitigate performance degradation due to limitations of computation power and memory, we propose two novel techniques, auxiliary shifting and early decision. Through both techniques, we can efficiently reduce the number of matching operations on resource-constrained systems. Experiments and performance analyses show that our proposed system achieves a maximum speedup of 2.14 with an IoT object and provides scalable performance for a large number of patterns.
BACKGROUND KNOWLEDGE AND RELATED WORK
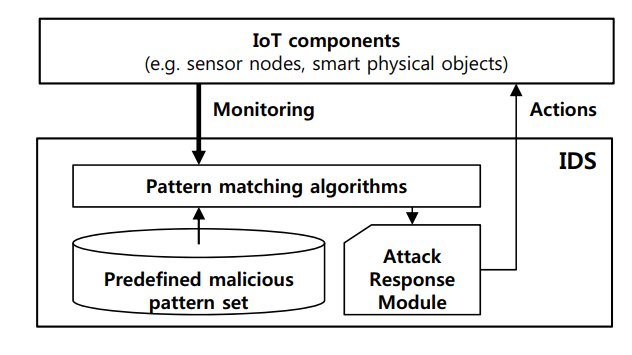
Figure 1. Architecture of intrusion detection system
Most intrusion detection systems detect malicious attacks by using pattern-matching algorithms with predefined malicious attack patterns, as shown in Figure 1. A multiple string-matching algorithm has been proposed to find all patterns of a finite pattern set P = {p1,p2, . . . ,pn}, in a text T = {t0,t1 . . . tl-1} of length l.
The patterns and text are sequences of characters from an alphabet Σ. The pattern set is defined according to empirically-determined malicious patterns (malicious signatures). The text is constituted by inbound and outbound packets from networks or system files inside target devices.
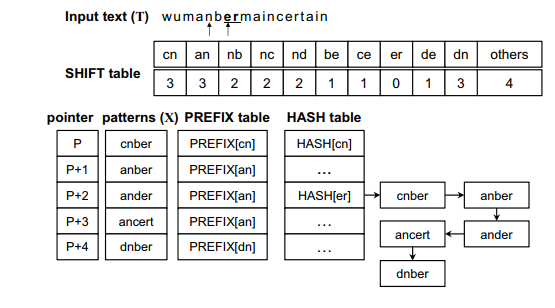
Figure 2. Wu–Manber multiple pattern-matching algorithm
The matching operation is represented through the example shown in Figure 2, and the original Wu–Manber algorithm is described as follows:
Step 1: Compute the hash value h from the current block and check the shift value of the index h in the shift table. If this shift value is zero, go to the next step. Otherwise, the block moves to the right by as many characters as the shift value. Repeat Step 1.
Step 2: Compute the hash value p from the prefix characters of the current block. Match p with the prefix of a pattern listed in the h index in the HASH table. If matched, go to the next step. Otherwise, traverse to the next pattern in the list until all patterns have been checked and then return to Step 1 after shifting the block by one character.
Step 3: The remaining characters of the pattern, the prefix for which has been matched with p, are compared with the characters of the input text. The character matching operation continues until a mismatch occurs. When a mismatch is found, return to Step 2. When all characters in the pattern match those of the input text, the pattern is found. Return to Step 2.
REDUCING UNNECESSARY MATCHING OPERATIONS ON EMBEDDED SYSTEMS
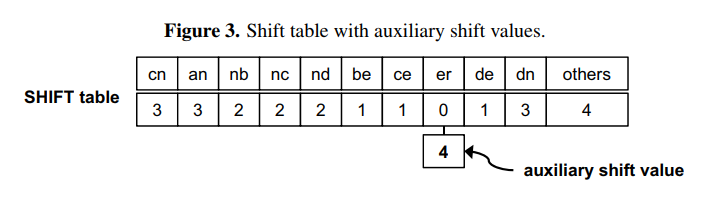
Figure 3. Shift table with auxiliary shift values
The character sequence of the initial block is “nb” in the input text (T). Both Wu–Manber and auxiliary shifting move the block to the right by two characters, since SHIFT [nb] = 2 in the shift table, as shown in Figure 3. The block then indicates the sequence “er” for which SHIFT [er] = 0. In this case, following the completion of Step 2 for the entry “er,” Wu–Manber shifts by only one character, and the next block has the sequence “rm.” On the other hand, auxiliary shifting shifts the block right by ASHIFT [er] = 4; the next block is “in.” Therefore, auxiliary shifting can skip three characters more than Wu–Manber.
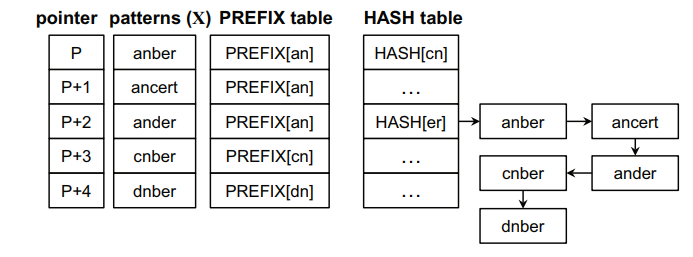
Figure 5. Sorted patterns and tables for the proposed algorithm
Figure 5 shows the result of applying the prefix sorting operation. All patterns in the figure have the same suffix value and are sorted according to their prefix values as well as remaining characters. As a result, a pattern should have a prefix and character values greater than or equal to any preceding patterns in the list.
The prefix matching operation on dnber can be skipped according to the proposed Step 2. However, early termination by comparing a prefix value is less helpful when the number of patterns increases and there are many patterns within the same prefix value. For this reason, we also propose the early decision for character matching operations. This means that a character matching operation on c is only processed for ancert. Moreover, no character matching operation occurs for ander, and prefix matching operations for ander, cnber and dnber can also be skipped.
THEORETICAL ANALYSIS
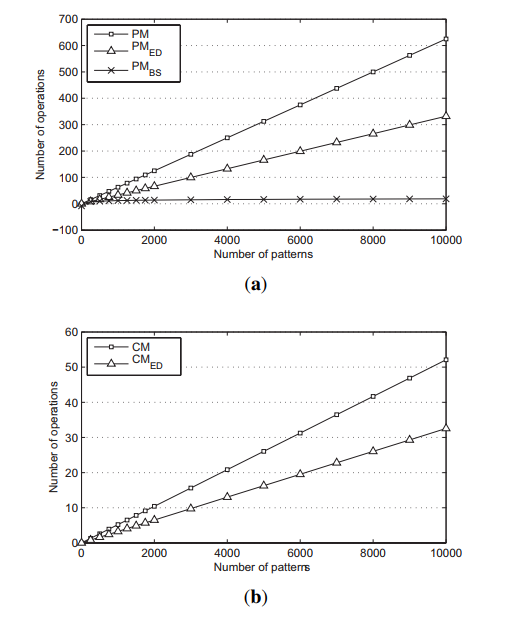
Figure 6. Number of matching operations based on theoretical analysis
(a) Prefix matching operation; (b) character matching operation.
The average number of operations for PM, PMED and PMBS are compared in Figure 6a, and the average number of operations for CM and for CMED are presented in Figure 6b. The size of the scan window and the prefix block are both set to two, and the number of characters is set to four. PMED and CMED reduce the number of required operations by nearly half. Moreover, PMBS shows very stable results, even when the number of patterns increases.
IMPLEMENTATION AND EVALUATION

Figure 7. Secured IoT device architecture
To evaluate the proposed security system for the IoT devices, we exploit a Raspberry Pi computing unit integrating the Omnivision 5647 sensor as the IoT device shown in Figure 7. Many of the IoT systems use Raspberry Pi as the smart devices. The micro-controller of this device consists of an ARM1176 700MHz processor, 256MB of synchronous dynamic random-access memory (SDRAM) and 2GB flash memory. Furthermore, this device is connected to the Internet using Wi-Fi.
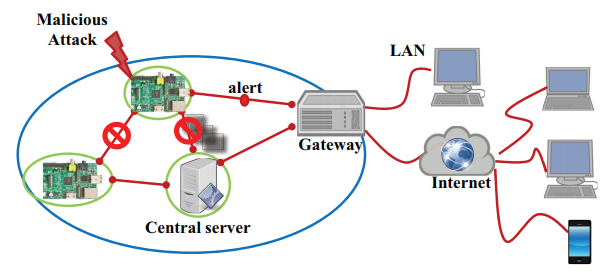
Figure 8. IoT network consisting of smart physical objects
Our malicious detection system concurrently runs on the device during processing its main work streaming the captured images. If the system detects a malicious attack, it stops processing and communicating with the server and alerts the gateway, as shown in Figure 8.
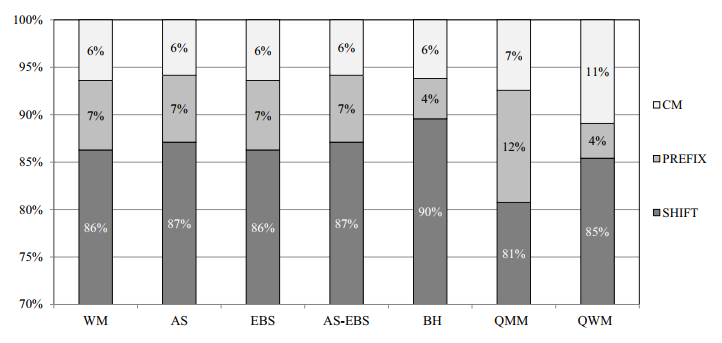
Figure 14. Detection accuracy of each matching steps
In this subsection, the detection accuracies of the algorithms are evaluated. In fact, the low detection accuracy will cause a large number of matching operations. All of the algorithms based on WM consist of three matching steps: SHIFT, PREFIX and character matching (CM), as mentioned before. We measure the detection accuracies for each of these steps, respectively, and show the results for Snort in Figure 14.
CONCLUSIONS
In this paper, we proposed a novel multiple pattern-matching algorithm for embedded security systems. Since the general embedded systems have a small size for the main memory, we limited the memory usage of the pattern-matching process. However, this limitation leads to performance degradation. To reduce the workload of the process, we proposed the auxiliary shifting method and the early decision scheme. The proposed methods successfully reduce the workload by skipping a large number of unnecessary matching operations through auxiliary shift values.
The early decision of the matching operations, according to the prefix and character values, reduces the complexity of the prefix and character matching operations to a logarithmic scale. Experiments showed that our proposed method achieved a speedup of up to 2.14 compared to the traditional pattern-matching algorithm given restricted resources. The proposed algorithm showed enhanced performance results especially when the number of patterns became large. Our proposed algorithm can thus contribute a high level of scalability to prevalent multiple pattern-matching algorithms.
Source: Yonsei University
Authors: Doohwan Oh | Deokho Kim | Won Woo Ro
>> Latest IoT Projects using Raspberry Pi for Engineering Students
>> IoT based Embedded Projects for Engineering Students with Free PDF Downloads
>> Latest 50+ IoT based Security Projects for Engineering Students
>> 200+ IoT Led Projects for Final Year Students
>> More Internet of Things (IoT) Diy Projects for Engineering Students