
ABSTRACT:
With the explosive increase in the amount of data being generated by various applications, large-scale distributed and parallel storage systems have become common data storage solutions and been widely deployed and utilized in both industry and academia.
While these high performance storage systems significantly accelerate the data storage and retrieval, they also bring some critical issues in system maintenance and management. In this dissertation, I propose three methodologies to address three of these critical issues.
First, I develop an optimal resource management and spare provisioning model to minimize the impact brought by component failures and ensure a highly operational experience in maintaining large-scale storage systems. Second, in order to cost-effectively integrate solid-state drives (SSD) into large-scale storage systems.
I design a holistic algorithm which can adaptively predict the popularity of data objects by leveraging the temporal locality in their access patterns and adjust their placement among solid-state drives and regular hard disk drives so that the data access throughput as well as the storage space efficiency of the large-scale heterogeneous storage systems can be improved.
Finally, I propose a new checkpoint placement optimization model which can maximize the computation efficiency of large-scale scientific applications while guarantee the endurance requirements of the SSD-based burst buffer in high performance hierarchical storage systems.
All these models and algorithms are validated through extensive evaluation using data collected from deployed large-scale storage systems and the evaluation results demonstrate our vimodels and algorithms can significantly improve the reliability and efficiency of large-scale distributed and parallel storage systems.
OPTIMAL RESOURCE MANAGEMENT AND SPARE PROVISIONING:
The Overview:
The design and procurement of large-scale storage systems are complex in nature. When faced with multi-faceted considerations, system designers usually cope with the challenges by adopting an ad hoc process that is a combination of back of the envelope calculations and the reliance on past experiences.
Factors Affecting the Reliability of Large-Scale Storage Systems:
In order to design optimal initial and continuous resource management and provisioning policies, we need to have a comprehensive understanding on system architectures, device failures, failure dependencies and propagation. These are the factors that have most significant impact on reliability of large-scale storage systems.
System architectures
System architecture plays an important role in the reliability of large-scale storage systems. For the convenience of replacing failed components in the system, hardware devices are usually encapsulated as field replaceable unit(FRU).
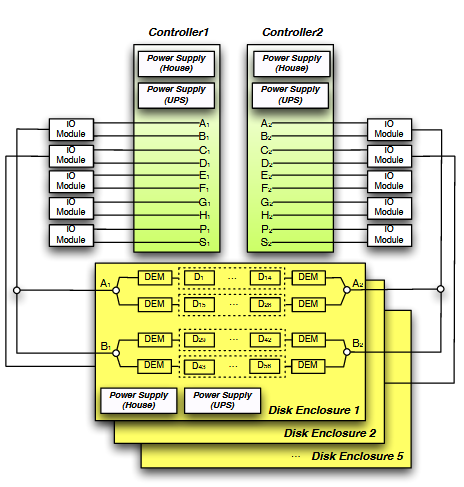
Spider I S2A 9900 Architecture.
Initial Provisioning:
Provisioning an HPC storage system for initial deployment involves understanding the tradeoffs between performance, cost, capacity and reliability. Often times, system architects are provided with a fixed budget for an initial acquisition and deployment, with an emphasis on optimizing for performance and capacity.
Reliability characteristics at the SSU-level or at the system-level are also factored in during this phase, with vendor support and spare part pools as the primary vehicles for maintaining system reliability. In this section, we attempt to reconcile these factors for an initial deployment, and study their interplay.
Continuous Provisioning:
Ideally, if we have an unlimited budget for spare provisioning, we can provide unlimited spares for each component in the system. However, in reality the budget is always limited, and we can only provision a limited number of spares. Therefore, the goal of continuous provisioning policy is to explore such dynamics under constraints.
OPTIMAL WORKLOAD-ADAPTIVE DATA PLACEMENT:
Problem Formulation:
With the development of storage technologies, SSDs have been eventually exploited by large-scale storage systems, as typically they can provide much higher I/O performance compared to conventional hard drives Park and Shen (2009b).
However, SSDs are also limited in capacity and much more expensive than hard disk drives, meaning that it is not yet practical to use them to completely replace conventional hard disks.
System Model:
The system model of our optimal workload-adaptive data placement is built upon several assumptions. First, the I/O workloads from user applications include both read and write operations, and the access pattern of these I/O operations could be either sequential or random.
This assumption is often true in realistic I/O workloads collected from large-scale data centers, web server clusters and HPC environments. Second, the modern large-scale storage systems are usually object-based, in which the minimal data unit is called object.
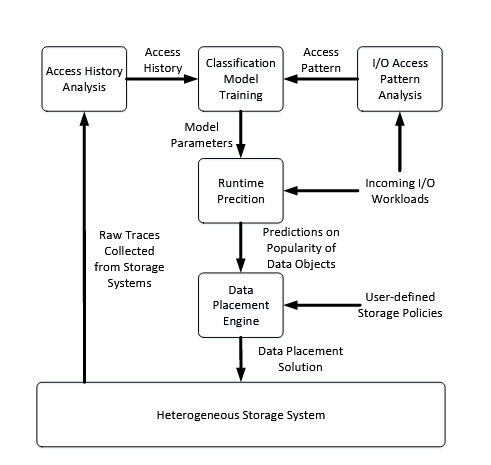
The System Model.
Algorithm Design:
Ideally,if we can record all access history of each data object, we can have the most accurate prediction on future data access. However, in reality it may not be practical to record even a relatively long access history for each data object since the trace collection overhead could be huge in that case.
Evaluation:
In this section, we present the evaluation results of the proposed data placement and replication algorithms
Evaluation on adaptive data replication
We evaluate the impact of our adaptive data placement on storage space efficiency and data availability through trace-driven event-based simulation. Both the failure logs and I/O traces used in our simulation were collected from deployed large-scale storage systems.
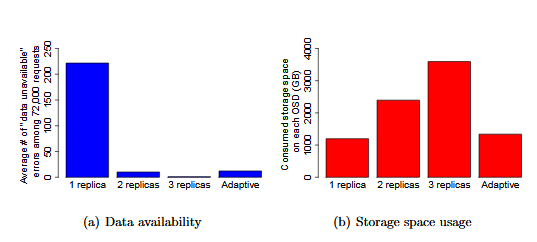
Data Availability and Storage Space Efficiency Achieved by Different Data Replication Schemes.
OPTIMAL CHECKPOINT PLACEMENT WITH GUARANTEED BURST BUFFER ENDURANCE:
The Overview:
Large-scale high performance computing (HPC) systems usually support running tens of scientific simulations on hundreds of thousands of compute nodes simultaneously. Due to the scale of both hardware and software components involved, failures are common and a fact of life in large-scale HPC systems’ daily operation.
Checkpoint Placement Optimization with Guaranteed Burst Buffer Endurance:
All existing studies assume that the burst buffer is used to absorb all checkpoint data from the HPC systems and only some of the checkpoints (e.g. every n-th checkpoint) are flushed from the burst buffer to the underlying parallel file systems for backup.
In that case, if multiple jobs that all produce large amounts of checkpoint data execute concurrently, then it becomes very challenging to maintain the burst buffer endurance requirements without negatively affecting the computational efficiency.
Adaptive Checkpoint Placement for Optimal HPC System and Burst Buffer Usage:
Assuming runtime characteristics, such as failure rates, job size, checkpoint size, of scientific applications are given, we can solve the above optimization model and determine the checkpoint interval and the percentage of checkpoint data that should be stored on the burst buffer on a per job basis. However, in practice, some of these runtime characteristics cannot be obtained before execution and others vary with time.
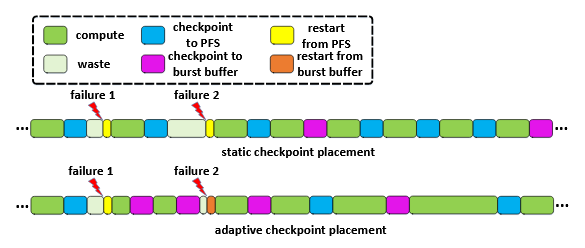
Static/adaptive Checkpoint Placement.
Evaluation:
In this section, we evaluate our adaptive checkpoint placement algorithm through event-based simulation and the failure traces collected from Titan supercomputer are used to drive the simulation.
Evaluation results
We first evaluate the average I/O workloads the burst buffer burdens with when different checkpoint placement models or algorithms are used by the scientific computation jobs.
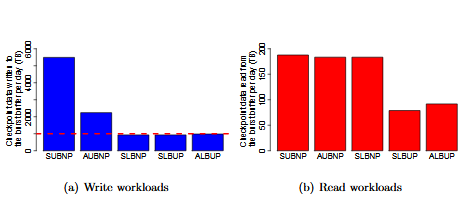
Average Amount of Checkpoint Data Written to and Read from the Burst Buffer per day when Different Checkpoint Placement Models or Algorithms are used.
CONCLUSION:
In this dissertation, I focus on the following three critical issues that commonly exist in maintaining and managing large-scale storage systems: 1) How to minimize the impact brought by component failures and ensure a highly operational experience in maintaining large-scale storage systems? 2) How to cost-effectively integrate solid-state drives (SSD) into large-scale storage system to improve system performance and efficiency? 3) How to maximize computation efficiency of large-scale scientific applications while guarantee the endurance requirements of the SSD-based burst buffer in high performance hierarchical storage systems? In order to solve these issues, I propose multiple novel models and algorithms.
One of the major challenges I encountered was how to evaluate these models and algorithms, as those deployed large-scale storage systems are seldom open to public, let alone allowed to make some changes to them. Therefore, all the models and algorithms proposed in my dissertation have been evaluated through simulation.
In order to guarantee the fidelity of the simulation results, I setup the simulation based on the real parameters of those deployed large-scale storage systems and use the data collected from the real storage systems to validate the simulation results. The evaluation results demonstrate that: 1) the simulation results are comparable with data gathered from real system measurement, 2) these proposed models and algorithms can significantly improve the reliability and efficiency of large-scale storage system.
Source: University of Tennessee
Author: Lipeng Wan