
ABSTRACT:
Mind reading encompasses our ability to attribute mental states to others, and is essential for operating in a complex social environment. The goal in building mind reading machines is to enable computer technologies to understand and react to people’s emotions and mental states.
This paper describes a system for the automated inference of cognitive mental states from observed facial expressions and head gestures in video. The system is based on a multilevel dynamic Bayesian network classifier which models cognitive mental states as a number of interacting facial and head displays.
Experimental results yield an average recognition rate of 87.4% for 6 mental states groups:agreement, concentrating, disagreement, interested, thinking and unsure Real time, unobtrusiveness and lack of reprocessing make our system particularly suitable for user-independent human computer interaction.
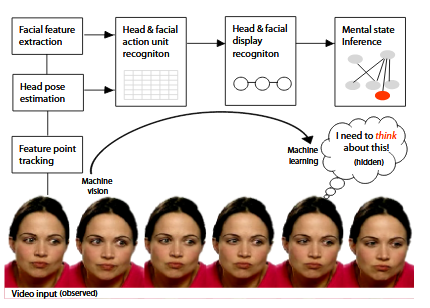
Block diagram of the automated mind reading system.
HEAD AND FACIAL ACTION UNIT ANALYSIS:
Twenty four facial landmarks are detected using a face template in the initial frame, and their positions tracked across the video. The system builds on Facestation, a feature point tracker that supports both real time and offline tracking of facial features on a live or recorded video stream.
Extracting Head Action Units:
Natural human head motion typically ranges between 70-90o of downward pitch, 55o of upward pitch, 70o of yaw (turn), and 55o of roll(tilt), and usually occurs as a combination of all three rotations. The output positions of the localized feature points are sufficiently accurate to permit the use of efficient, image-based head pose estimation.
Extracting Facial Action Units:
Facial actions are identified from component-based facial features (e.g.mouth) comprised of motion, shape and colour descriptors. Motion and shape-based analysis are particularly suitable for a real time video system, in which motion is inherent and places a strict upper bound on the computational complexity of methods used in order to meet time constraints.
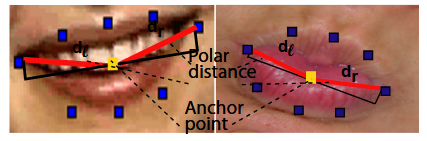
Polar Distance in Determining a Lip Corner Pull and Lip Pucker.
HEAD AND FACIAL DISPLAY RECOGNITION:
Facial and head actions are quantized and input into left-to-right HMM classifiers to identify facial expressions andhead gestures. Each is modelled as a temporal sequence of action units (e.g. a head nod is a series of alternating up and down movement of the head).
COGNITIVE MENTAL STATE INFERENCE:
The HMM level outputs a likelihood for each of the facial expressions and head displays. However, on their own, each display is a weak classifier that does not entirely capture an underlying cognitive mental state. Bayesian networks have successfully been used as an ensemble of classifiers, where the combined classifier performs much better than any individual one in the set.
EXPERIMENTAL EVALUATION:
For our experimental evaluation we use the Mind reading dataset (MR). MR is a computer based guide to emotions primarily collected to help individuals diagnosed with Autism recognize facial expressions of emotion. A total of 117 videos, recorded at 30 fps with durations varying between 5 to 8 seconds, were picked for testing.

ROC Curves for Head and Facial Displays.
Display Recognition:
We evaluate the classification rate of the display recognition component of the system on the following 6 displays: 4 head displays (head nod, head shake, tilt display, turn display) and 2 facial displays (lip pull, lip pucker). The classification results for each of the displays are shown using the Receiver Operator Characteristic (ROC) curves.
Mental State Recognition:
We then evaluate the overall system by testing the inference of cognitive mental states, using leave-5-out cross validation shows the results of the various stages of the mind reading system for a video portraying the mental state choosing, which belongs to the mental state group thinking. The mental state with the maximum likelihood over the entire video (in this case thinking ) is taken as the classification of the system.
APPLICATIONS AND CONCLUSION:
The principle contribution of this paper is a multi-level DBN classifier for inferring cognitive mental states from videos of facial expressions and head gestures in real time. The strengths of the system include being fully automated, user-independent, and supporting purposeful head displays while de-coupling that from facial display recognition.
We reported promising results for 6 cognitive mental states on a medium-sized posed dataset of labelled videos. Our current research directions include:
- Testing the generalization power of the system by evaluating a larger and more natural dataset.
- Exploring the within-class and between-class variation between the various mental state classes, perhaps by utilizing cluster analysis and/or unsupervised classification.
- Adding more mental state models such as comprehending, bored and tired, which like the ones already reported in this paper are relevant in an HCI context.
On the applications front we are working on integrating the system with instant messaging to add spontaneity of interaction. In addition, we are building a prototype of an “emotional hearing aid”, an assistive tool for people diagnosed with Asperger’s Syndrome designed to provide advice on emotion understanding from video. We believe that the work presented is an important step towards building mind reading machines.
Source: University of Cambridge
Authors: R. El Kaliouby | P. Robinson