
ABSTRACT
We are entering a new era of computing technology, the era of Internet of Things (IoT). An important element for this popularization is the large use of off-the-shelf sensors. Most of those sensors will be deployed by different owners, generally common users, creating what we call the Collaborative IoT. This collaborative IoT helps to increase considerably the amount and availability of collected data for different purposes, creating new interesting opportunities, but also several challenges. For example, it is very challenging to search for and select a desired sensor or a group of sensors when there is no description about the provided sensed data or when it is imprecise.
Given that, in this work we characterize the properties of the sensed data in the Internet of Things, mainly the sensed data contributed by several sources, including sensors from common users. We conclude that, in order to safely use data available in the IoT, we need a filtering process to increase the data reliability. In this direction, we propose a new simple and powerful approach that helps to select reliable sensors. We tested our method for different types of sensed data, and the results reveal the effectiveness in the correct selection of sensor data.
RELATED WORK
There are at least two aspects to consider when we study sensing in the IoT environments. The first one is a proper sensor search and selection strategy to ensure the desired sensors are found. The second one deals with the quality of these selected sensors, since the behavior of a system depends completely on the observations it infers about the environment, which is based on the sensed data.
Solutions for Sensor Search and Selection
The first aspect that may affect the quality of the sensing is how to correctly match the expected data to the actually collected one. The description of the services plays a key role to this, since the richer the service description is the better its matching will be and, thus, it allows us to better interpret and understand the service itself. To address this problem, the solutions should begin by a proper description of the service functionalities.
Solutions for the Quality of Sensing in IoT
Besides the previously mentioned efforts about strategies for searching and selecting one or more sensors, considering specific contextual information from them, the current state of the art of a collaborative IoT environment is still far from providing complete information available. For instance, the most common pieces of information available from a sensor platform and middleware for an IoT application are the sensor location, sensor type, keywords and the data they generate.
CHARACTERIZING THE SENSED DATA
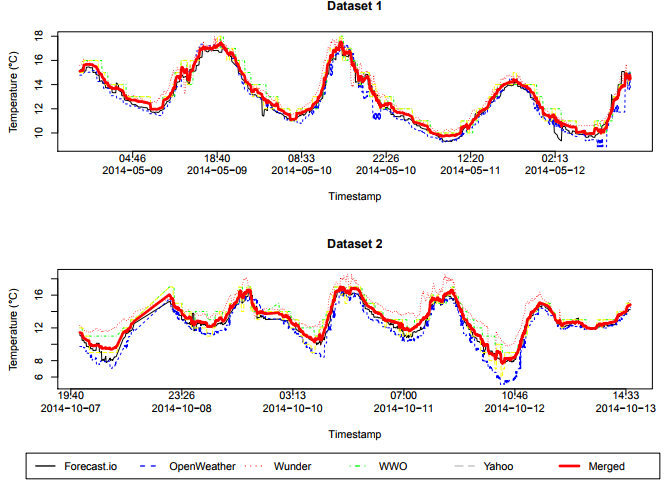
Figure 1. Comparison between five possible reference services and the average merged sample, for the two datasets
We considered the following five options of weather forecast services as our reference: Forecast.io, Open Weather, Weather Underground, World Weather Online and Yahoo Weather. As shown in Figure 1, all weather forecast services were similar in the period of the analysis. We have chosen the Forecast.io service as our reference data, since it is close to the average merged sample, with a mean squared error (MSE) of 0.0685161 for Dataset 1, and 0.1571421 for Dataset 2.
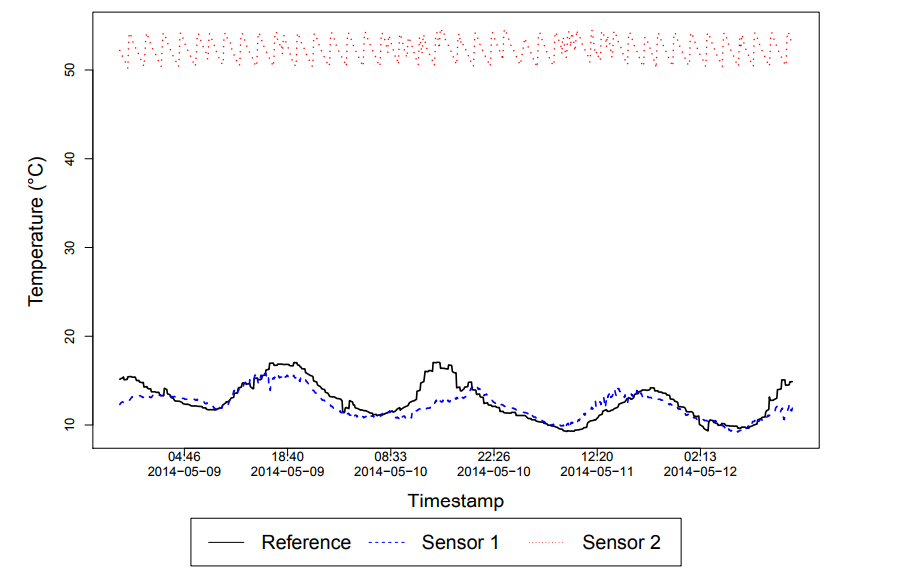
Figure 3. Different sensor readings for the “temperature” tag, but with different meanings (Dataset 1)
For example, Figure 3 shows different sensor data collected for temperature. While the blue dashed line (Sensor 1) means a sensor reading for an outdoor temperature, the red dotted line (Sensor 2) corresponds to a sensor reading for the temperature of a water tank. For this specific case, the data owner filled the description of the temperature data, but this is not the general case. The black solid line represents our reference data. This exemplifies the need for a specific sensor selection strategy for this kind of sensed data.
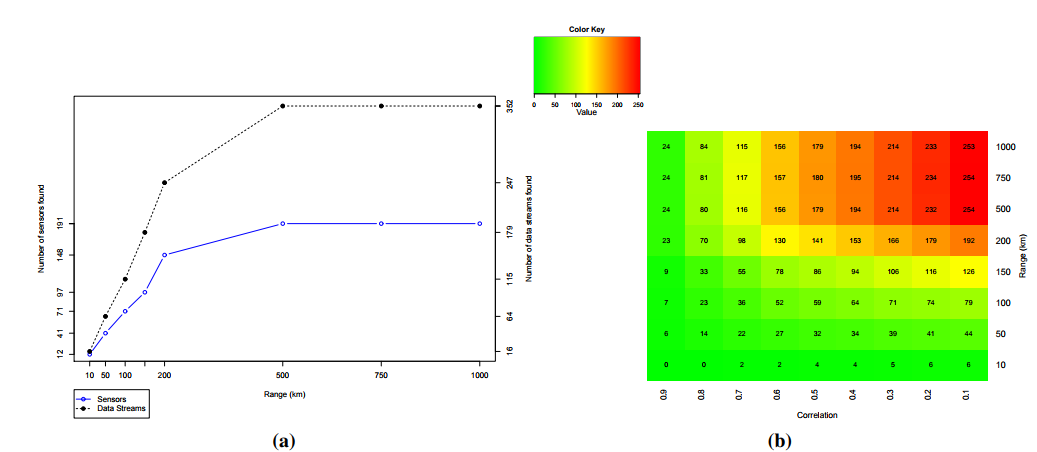
Figure 7. Analysis of the number of sensors found in Dataset 1
(a) Number of sensors and their data streams found for different sensor search ranges (Dataset 1); (b) Heat map for the number of data streams found when varying the range of the desired location area and the correlation coefficient limit (Dataset 1).
On the other hand, when we look at the bigger picture, we can observe some interesting patterns that can be used to handle this uncertainty. Figure 7a shows the sensors and their data streams found in Dataset 1. As we increase the range (distance in kilometers from the central coordinate point), the number of available sensors (feeds) and their data streams also increase. On average, a sensor provides approximately two data streams (1.84).
Applying the sample correlation coefficient r as a metric to filter the considered trusted data, we have the results showed in the heat map of Figure 7b, which represents the selected data streams when varying the range and the correlation coefficient limit l. From the set of all data streams in a given range, we selected those which give r ≥ l in comparison with the reference sensor data.
EVALUATION OF OUR APPROACHES
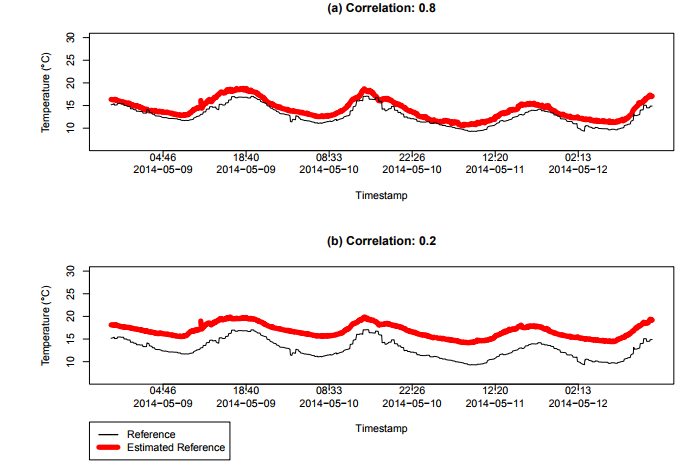
Figure 10. Estimation of the temperature ˆθ for two different correlation limits in a range of 100 km from the coordinates of London, UK, in Dataset 1
Figure 10(a) shows the sensors that are 0.8 positive correlated with this reference, resulting in a MSE = 2.244199. Figure 10(b) shows the same estimation process, but relaxing the correlation criterion, considering all sensors with correlation coefficient r ≥ 0.2 to the reference sensor, resulting in a MSE = 16.85198. As we can see, the more correlated the sensors are with the reference, the better the capacity of estimating ˆθ is. Figure 10 also shows that the estimation error increases as we consider more unreliable sensors.
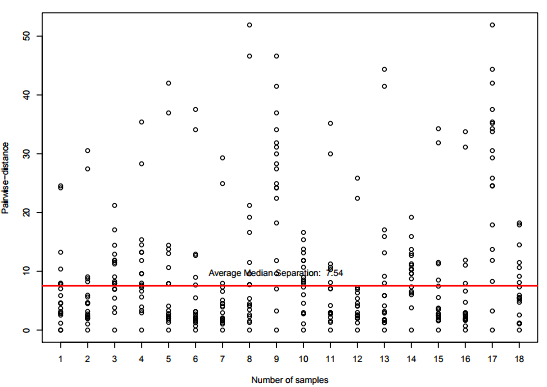
Figure 11. Pairwise-distances for temperature sensors in a range of 100 km from the coordinates of London, UK, in Dataset 2, considering only sensors with correlation r ≥ 0.8
For the temperature sensor selection, we considered the same steps and parameters of the previously mentioned experiment for Dataset 1. Figure 11 presents the resulting pairwise-distances for the 18 sensors found in Dataset 2. It is important to consider the time interval between collections, almost five months, to explain the difference in the number of detected sensors.
CONCLUSIONS
Dealing with the uncertainties of the sensed data in a collaborative IoT scenario is a new and important problem that must be considered prior to the development of systems that can benefit from this data. The core of ubiquitous computing systems is based on the knowledge they infer about the state of the physical environment, and thus, the reliability of the sensed data will directly impact the decisions and context-awareness of those systems.
In this work, we characterized the properties of the available sensed data from real deployed sensors in the current collaborative IoT for which we have a reference value. We conclude that, in order to safely use data available in the IoT, we need to perform a filtering process followed by a refinement of the selected data to increase its reliability. Thus, we proposed a simple and effective approach to select and refine the data from reliable sensors by a collaborative filtering technique.
Our assumption is that the combination of the readings for most of the reliable sensors converge to the correct value of the measured data. This hypothesis was validated through an experiment using data collected from real deployed sensors. The results show that the proposed method is a promising approach to select reliable sensors, regardless of having a controlled set of sensors or not. Even when mixing the available sensors with different data classes, the selection of the reliable data provides a good approximation of the assumed correct values, based on a reference sample.
When the number of selected sensors decreases, we may not have enough sensors and the collaborative filtering technique can not be expected to converge to the correct value of the given variable (in our example, environmental data). However, we can expect to have more sensors available in the future (possibly in the order of hundreds of millions), since we are entering a new era of computing technology with a very strong presence of the Internet of Things, and, thus, this issue will probably be minimized for different classes of sensor data.
Source: Universidade Federal de Minas Gerais
Authors: João B.Borges Neto | Thiago H.Silva | Renato Martins Assunção | Raquel A.F.Mini | Antonio A.F.Loureiro
>> 200+ IoT Led Projects for Final Year Students