
ABSTRACT
Robotic controllers have to execute various complex independent tasks repeatedly. Massive processing power is required by the motion controllers to compute the solution of these computationally intensive algorithms. General-purpose graphics processing unit (GPGPU)-enabled mobile phones can be leveraged for acceleration of these motion controllers.
Embedded GPUs can replace several dedicated computing boards by a single powerful and less power-consuming GPU. In this paper, the inverse kinematic algorithm based numeric controllers is proposed and realized using the GPGPU of a handheld mobile device. This work is the extension of a desktop GPU-accelerated robotic controller presented at DAS’16 where the comparative analysis of different sequential and concurrent controllers is discussed.
First of all, the inverse kinematic algorithm is sequentially realized using Arduino-Due microcontroller and the field-programmable gate array (FPGA) is used for its parallel implementation. Execution speeds of these controllers are compared with two different GPGPU architectures (Nvidia Quadro K2200 and Nvidia Shield K1 Tablet), programmed with Compute Unified Device Architecture (CUDA) computing language. Experimental data shows that the proposed mobile platform-based scheme outperforms the FPGA by 5 × and boasts a 100 × speedup over the Arduino-based sequential implementation.
RELATED WORK
Diversified approaches to control a robotic manipulator have been proposed. However, there is much less of a contribution in the area of mobile GPU-based motion controllers. The inverse kinematic implementation of a four-wheeled mobile robot is presented. A master–slave configuration-based distributed control mechanism is employed where the master controller is used to compute the inverse kinematic model from the movement vector of the robotic platform, and the slave controllers are used to drive the motors.
CONTROL ALGORITHM
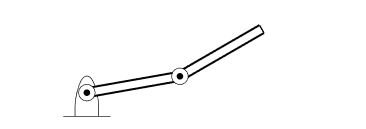
Figure 1. Two degree-of-freedom planar robotic arm
A simple structure of robotic arm having two joints is considered in this work for the performance evaluation of the GPGPU-based independent joint controller as shown in Figure 1. The proposed scheme can also be extended to other complex robotic structures having multiple joints.
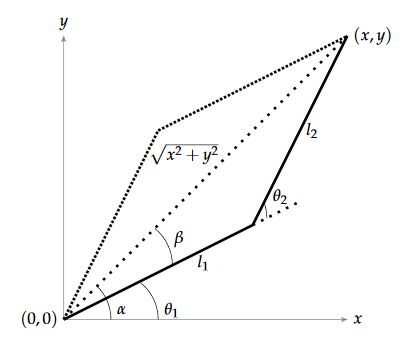
Figure 2. Geometric representation of arm
Moreover, l1 and l2 are the lengths of robotic arms as shown in Figure 2. It can be noted that excepting the boundaries, there will always be two solutions (the elbow up and elbow down configuration) to reach the required location as shown in Figure 2, but the controller will choose the one which will be closest to the current position.
IMPLEMENTATION OF ALGORITHM ON SEQUENTIAL CONTROLLER (ARDUINO-DUE)
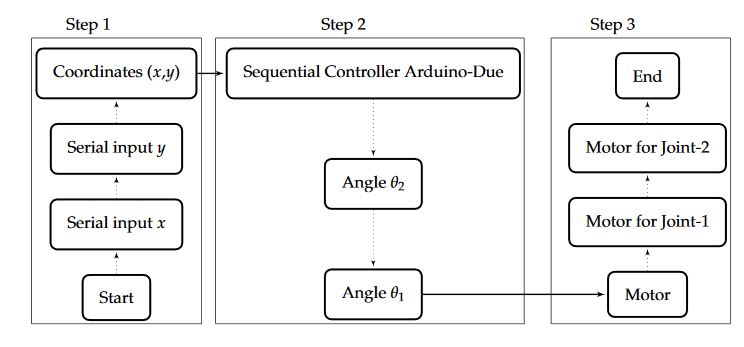
Figure 4. Flow chart of sequential implementation
For the sequential implementation of inverse kinematic algorithm, the widely-used powerful microcontroller board Arduino-Due is selected and programmed using C-based language. All the programs and algorithms burned in this controller are executed sequentially as shown in Figure 4. First of all, the waypoints generated by the CAD/CAM software are serially received by the Arduino. These received coordinates (x and y) are used by the microcontroller to compute the angles sequentially, and then signals are sent to the motors of robotic arm accordingly.
IMPLEMENTATION OF THE ALGORITHM ON THE INDEPENDENT JOINT CONTROLLER (FPGA)
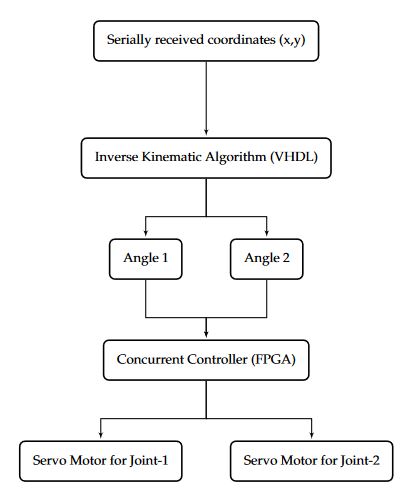
Figure 5. Flow chart of independent joint calculation using a field-programmable gate array (FPGA)
The desired algorithm can be divided into smaller tasks and executed faster than a sequential implementation using concurrent processes in VHDL. Concurrent execution capability of VHDL makes it the best choice to execute the algorithms and compute the solution of complex mathematical equations. Moreover, concurrent language can execute multiple blocks of code in parallel. As shown in Figure 5, both angles of inverse kinematic can be computed in VHDL independently and similarly, control of motors can also be parallelized using FPGA.
IMPLEMENTATION OF ALGORITHM ON GENERAL PURPOSE GRAPHICS PROCESSING UNIT
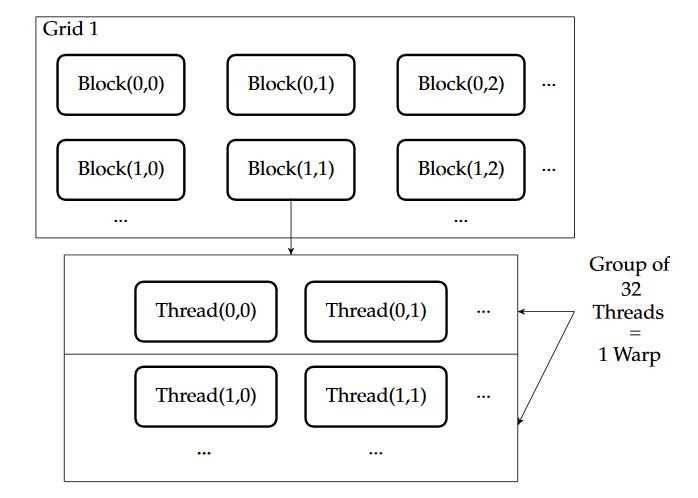
Figure 9. Representation of a graphics processing unit (GPU) structure
GPU is a multicore, multithreaded hardware which can outperform the other embedded controllers using its massive concurrent computational resources. Computing resources of GPU are arranged in multiple grids of completely independent blocks. A single block is composed of multiple threads which can only communicate within their block as shown in Figure 9.
COMPARATIVE ANALYSIS OF EMBEDDED CONTROLLERS
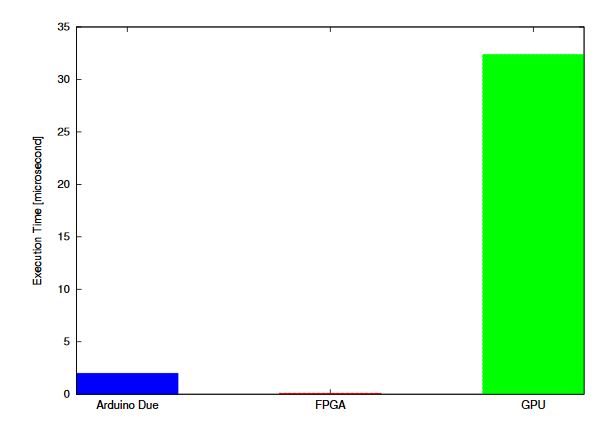
Figure 12. Comparison of results for single test points
CUDA implementation for a single test point (using a single thread) is slower than the concurrent implementation of FPGA as shown in Figure 12. This is because the embedded controllers discussed in previous sections are suitable for single instruction single data (SISD) arithmetic and logical operations while the GPU is suitable for SIMD executions.
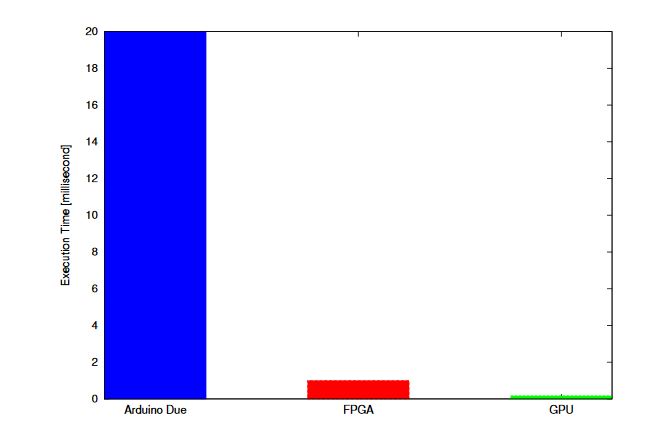
Figure 13. Comparison of results for 10,000 test points
The execution time of all discussed controllers would increase linearly with the addition of test points because these controllers are based on SISD architecture where the solution of each test point is computed sequentially. However, GPU can compute the solution of thousands of test points independently using its SIMT architecture. Figure 13 illustrates the capability of GPGPU to calculate the solution of large data set more efficiently in terms of time.
HARDWARE REALIZATION OF GPGPU-BASED ROBOTIC MANIPULATOR
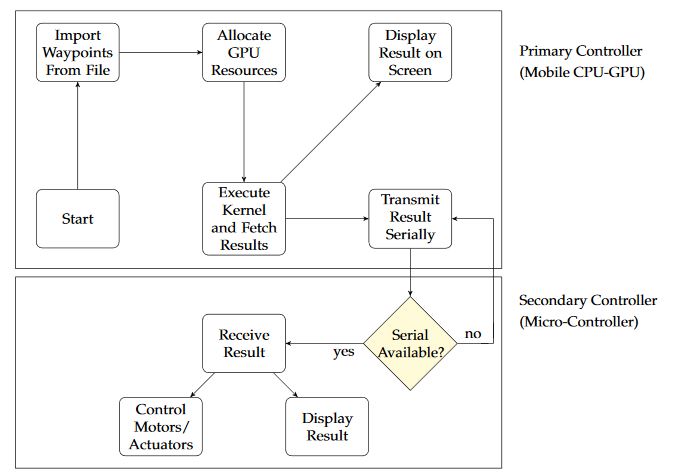
Figure 15. GPU as primary and microcontroller as secondary controller
The proposed robotic manipulator is physically realized by interfacing a GPGPU-enabled embedded device with microcontroller where the intensive computations are performed on GPGPU and results are transferred serially to the microcontroller (Arduino-Due) to control the motors of the system. GPGPU computed the solution of the algorithm as primary controller and Arduino-Due controlled the motors as a secondary controller as shown in Figure 15.
CONCLUSIONS
This paper presents a mobile GPU-based robotic controller for the fast solution of a computationally large and data-intensive inverse kinematic algorithm. The proposed scheme is physically realized by interfacing a GPGPU-enabled embedded device with microcontroller where the intensive computations are performed on a GPGPU and a microcontroller is used to control the motors/actuators of the system.
This inverse kinematic algorithm is implemented in widely used sequential and concurrent controllers for the comparative analysis. The proposed GPGPU-based scheme shows substantial improvement in execution speed over other controllers that is needed for a robotic application. Results conclude that the proposed scheme can show promising results in various applications where the computational burden of a numeric controller can be offloaded to a powerful mobile GPU.
Source: University of Central Punjab
Authors: Syed Tahir Hussain Rizvi | Gianpiero Cabodi | Denis Patti | Muhammad Majid Gulzar