
ABSTRACT
The interaction between information technology and physical world makes Cyber-Physical Systems (CPS) vulnerable to malicious attacks beyond the standard cyber attacks. This has motivated the need for attack-resilient state estimation. Yet, the existing state-estimators are based on the non-realistic assumption that the exact system model is known.
Consequently, in this work we present a method for state estimation in presence of attacks, for systems with noise and modeling errors. When the the estimated states are used by a state-based feedback controller, we show that the attacker cannot destabilize the system by exploiting the difference between the model used for the state estimation and the real physical dynamics of the system.
Furthermore, we describe how implementation issues such as jitter, latency and synchronization errors can be mapped into parameters of the state estimation procedure that describe modeling errors, and provide a bound on the state-estimation error caused by modeling errors. This enables mapping control performance requirements into real-time (i.e., timing related) specifications imposed on the underlying platform. Finally, we illustrate and experimentally evaluate this approach on an unmanned ground vehicle case-study.
MOTIVATION AND PROBLEM DESCRIPTION
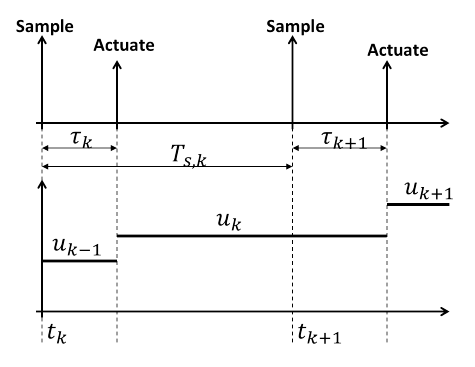
Figure 1: Scheduling sampling and actuation.
We first consider setups where all plant’s output are sampled (i.e., measured) at times tk, k ≥ 0, and where all actuators apply newly calculated inputs at times tk + τk, k ≥ 0, as shown in Fig. 1. We denote the kth sampling period of the plant by Ts;k = tk+1 tk, and note that the input signal will have the form shown in Fig. 1(b). Using the approach we describe the system as,
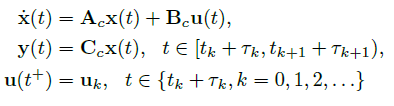
where u(t+) is a piecewise continuous function that only changes values at time instances tk + τk, k ≥ 0.
RESILIENT STATE ESTIMATION IN PRESENCE OF MODELING ERRORS
As illustrated, the effects of the input vectors uk are taken into account when computing the matrix Yt;N. Thus, in the rest of this paper (unless otherwise stated) we will assume that uk = 0 for all k ≥ 0. In addition, to further simplify the notation we consider the case for t = N-1, meaning that our goal is to obtain x0, and we denote the matrices Yt;N ;Et;N and ΦN(x) as Y;E and Φ (x), respectively.
We assume that the state of the plant at k = 0 is x0 and that the system evolves for N steps as specified (for uk = 0) for some attack vectors e0,…, eN-1 applied on the sensors from set K ={ si1,…, siq } ⊆ S, where |K| ≤ qmax, and the corresponding matrix E = |e0||e1| …|eN-1|. Furthermore, we assume that |wk|≤ εwk and |vk| ≤ εvk for k = 0; 1; :::;N – 1, and we define,
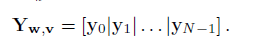
ROBUSTNESS OF P0, Δ(Y) STATE ESTIMATION
In this section, we provide robustness analysis for P0, Δ(Y) optimization problem when matrix Δ satisfies conditions from the previous section. We start by showing that the attacker cannot exploit the modeling errors to destabilize the system before we present a method to bound the error caused by noise and modeling errors – i.e., we provide a bound on ||x0, Δ – x0||2.
EVALUATION

To evaluate conservativeness of the error bound obtained using Algorithm 1 we consider two types of systems – systems with n = 10 states and p = 5 sensors, and with n = 20 states and p = 11 sensors. For each system type we randomly generated 100 systems with measurement models satisfying that the rows of the C matrix have unit magnitude and matrices had Δ elements between 0 and 2.
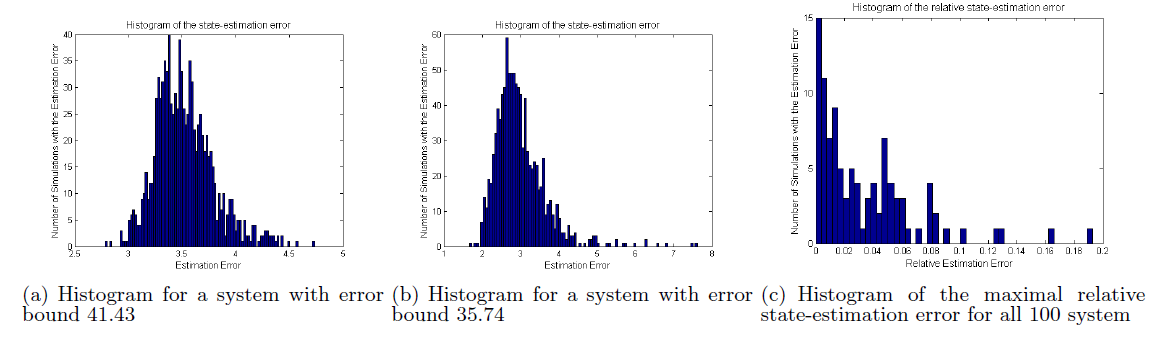
Figure 2: Simulation results for 1000 runs of 100 randomly selected systems with n = 10 states and p = 5 sensors.
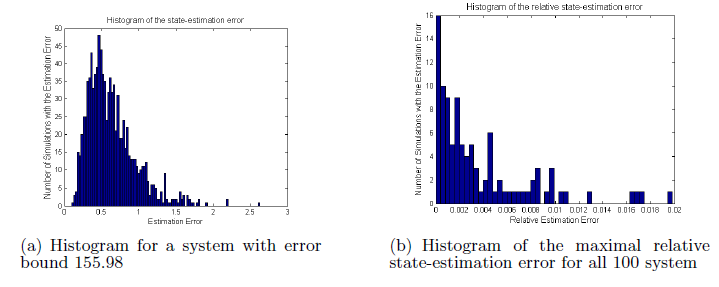
Figure 3: Simulation results for 1000 runs of 100 randomly selected systems with n = 20 states and p = 11 sensors.
In both simulations and Algorithm 1 executions, we considered the case when window size N is equal to the number of system states (i.e., N = n). Comparison between the bounds provided by Algorithm 1 and simulation results are shown in Fig. 2 and Fig. 3.
CASE STUDY
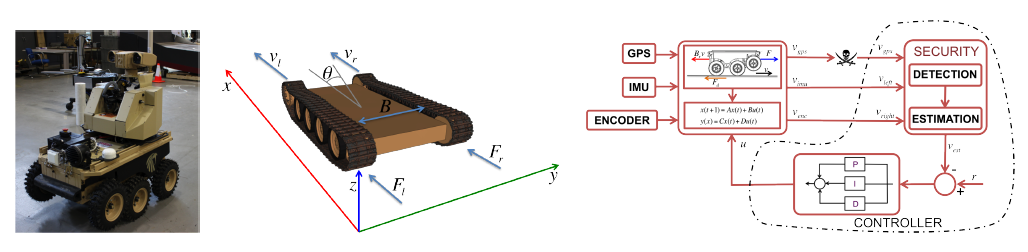
Figure 4: LandShark unmanned ground vehicle; (a) The vehicle; (b) Coordinate system and variables used to derive the model; (c) Control system diagram used for cruise control.
We illustrate the development framework on a design of secure cruise control of the Land Shark vehicle, a fully electric Unmanned Ground Vehicle (UGV) shown in Fig.4(a). To obtain a dynamical model of the vehicle we used the standard differential drive vehicle model (Fig. 4(b)). On the Land Shark, the CPU that implements the state estimation and controller procedure is connected to all sensors through independent serial buses, while the motors are connected to the CPU via motor drivers (as presented in Fig. 4(c)).
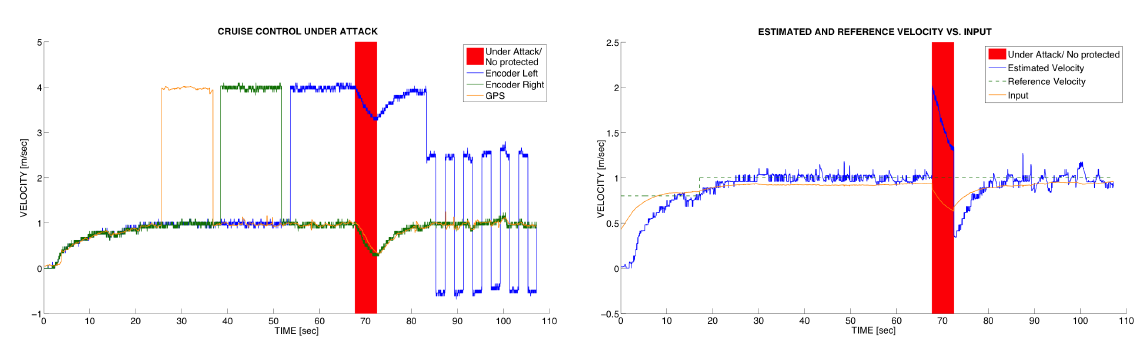
Figure 6: Experimental results; (a) Comparison of velocity estimated from the encoders’ and GPS measurements; (b) Reference speed, the estimated speed, and the input applied to the motors.
From the developed GUI we demonstrate that the robot can reach and maintain the desired reference speed even when one of the sensors is under attack, as shown in Fig. 6. Fig. 6(a) presents speed estimates from the encoders and GPS; each of the sensors has been attacked at some point, with attacks such that their measurements would result in the speed estimate equal to 4 m/s, except in the last period of the simulation when we have switched to an alternating attack on the encoder left. However, as shown in Fig. 6(b) when the attack-resilient controller is active the robot reaches and maintains the desired speed of 1 m/s.
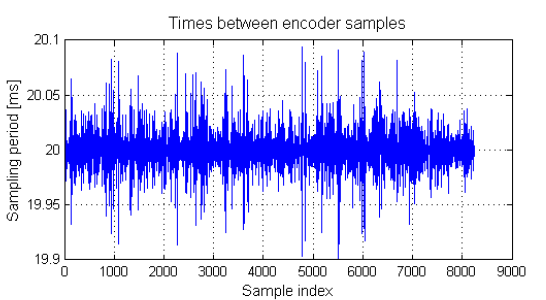
Figure 7: Times between consecutive left en-coder measurements.
In addition, there is a huge discrepancy between sensors’ sampling jitters. For example, encoders’ sampling jitters are bounded by 100 μs (as shown in Fig. 7), while GPS has highly variable jitter with maximal values up to 125 ms. Therefore, it is not possible to use the idealized discrete-time model, but rather the full input compensation has to be done, before the state-estimator is executed.
CONCLUSION
In this paper, we have considered the problem of attack resilient state estimation in systems with noise and where the exact model of the system dynamics is not known. We have described a l0-norm based state estimator that can be used for these systems, and showed that the attacker cannot exploit the noise and limitations in model accuracy to destabilize the system.
Furthermore, we have provided an algorithm to derive a bound for the state estimation error caused by noise and modeling errors, and presented a procedure to map these bounds into a set of implementation specifications imposed on the underlying platform. Finally, we have illustrated our approach by designing an attack-resilient constant speed cruise controller for unmanned ground vehicle.
We have shown that the presented l0-norm optimization procedure for state estimation can be formulated as a mixed integer linear program. Although there exist efficient MILP solvers, MILPs are effectively NP hard.
Therefore, the natural next step would include transforming the l0 state estimator into a convex program based on l1=lr optimization (e.g., r = 2) as done. In this case, providing a bound for the state-estimation error when the l1=lr convex relaxation is used will be an avenue for future work.
Source: University of Pennsylvania
Authors: Miroslav Pajic | James Weimer | Nicola Bezzo | Paulo Tabuada | Oleg Sokolsky | Insup Lee | George Pappas
>> More B.Com CA Final Year Projects