
ABSTRACT
Multicore processors are becoming ubiquitous, and it is becoming increasingly common to run multiple real-time systems on a shared multicore platform. While this trend helps to reduce cost and to increase performance, it also makes it more challenging to achieve timing guarantees and functional isolation.
One approach to achieving functional isolation is to use virtualization. However, virtualization also introduces many challenges to the multicore timing analysis; for instance, the overhead due to cache misses becomes harder to predict, since it depends not only on the direct interference between tasks but also on the indirect interference between virtual processors and the tasks executing on them.
In this paper, we present a cache-aware compositional analysis technique that can be used to ensure timing guarantees of components scheduled on a multicore virtualization platform. Our technique improves on previous multicore compositional analyses by accounting for the cache-related overhead in the components’ interfaces, and it addresses the new virtualization specific challenges in the overhead analysis. To demonstrate the utility of our technique, we report results from an extensive evaluation based on randomly generated workloads.
SYSTEM DESCRIPTIONS
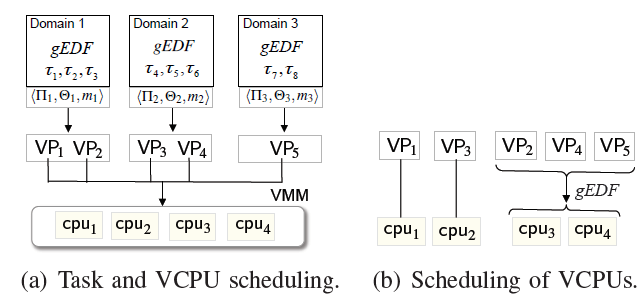
Fig. 1: Compositional scheduling on a virtualization platform.
We consider a hybrid version of the Earliest Deadline First (EDF) strategy. As is shown in Fig. 1, tasks within each domain are scheduled on the domain’s VCPUs under the global EDF (gEDF) scheduling policy. The VCPUs of all the domains are then scheduled on the physical cores under a semi-partitioned EDF policy: each full VCPU is pinned (mapped) to a dedicated core, and all the partial VCPUs are scheduled on the remaining cores under gEDF.
DETERMINISTIC MULTIPROCESSOR PERIODIC RESOURCE MODEL
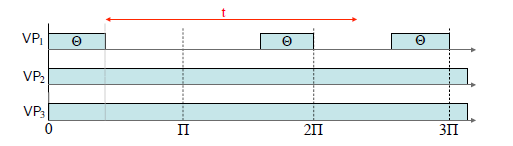
Fig. 2: Worst-case resource supply pattern of μ = (Π,Θ,m).
Observe that the partial processor of μ is represented by a single-processor periodic resource model Ω = (Π;Θ). (However, it can also be represented by any other single processor resource model, such as EDP model). Based on this characteristic, we can easily derive the worst-case supply pattern of μ (shown in Figure 2) and its supply bound function, which is given by the following lemma.
OVERHEAD-FREE COMPOSITIONAL ANALYSIS
In this section, we present our method for computing the minimum-bandwidth DMPR interface for a component, assuming that the cache-related overhead is negligible. The overhead-aware interface computation is considered in the next sections. We first recall some key results for components that are scheduled under gEDF.
- Component schedulability under gEDF
- DMPR interface computation
CACHE-RELATED OVERHEAD SCENARIOS
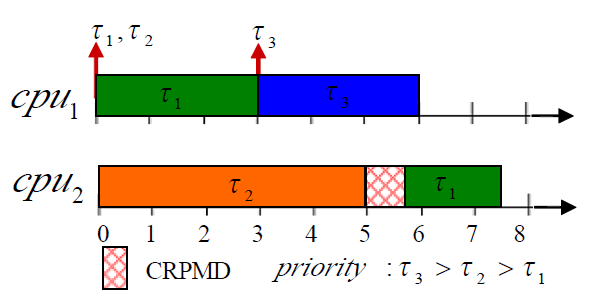
Fig. 3: Cache-related overhead of a task-preemption event.
Fig. 3 illustrates the worst-case scenario of the overhead caused by a task-preemption event. In the figure, a preemption event of τ1 happens at time t = 3 when τ3 is released (and preempts τ1). Due to this event, τ1 experiences a cache miss at time t = 5 when it resumes. Since τ1 resumes on a different core, all the cache blocks it will reuse have to be reloaded into new core’s cache, which results in cache-related preemption/ migration overhead on τ1.

Fig. 4: Cache overhead due to a VCPU-preemption event.
Example 1. The system consists of three domains D1-D3. D1 has VCPUs VP1 (full) and VP2 (partial); D2 has VCPUs VP3 (full) and VP4 (partial); and D3 has one partial VCPU VP5. The partial VCPUs of the domains – VP2(5; 3), VP4(8; 3) and VP5(6; 4) – are scheduled under gEDF on cpu1 and cpu2, as is shown in Fig. 4(a). In addition, domain D2 consists of three tasks, τ1 (8; 4; 8), τ2(6; 2; 6) and τ3(10; 1:5; 10), which are scheduled under gEDF on its VCPUs (Fig. 4(b)).
TASK-CENTRIC COMPOSITIONAL ANALYSIS
In this section, we present a task-centric approach to account for the overhead in the interface computation. The idea is to inflate the WCET of every task in the system with the maximum overhead it experiences within each of its periods.
As was discussed in Section V, the overhead that a task experiences during its lifetime is composed of the overhead caused by task-preemption events, VCPU-preemption events and VCPU-completion events. In addition, when one of the above events occurs, each task τk experiences at most one cache miss and, hence, a delay of at most Δcrpmd. From Lemmas 9, 11 and 12, we conclude that the maximum overhead τk experiences within each period is
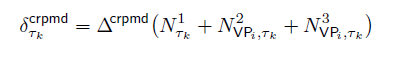
where VPi is the partial VCPU of the domain of τk.
MODEL-CENTRIC COMPOSITIONAL ANALYSIS
Recall that each VCPU-stop event (i.e., VCPU-preemption or VCPU-completion event) of VPi causes at most one cache miss for at most two tasks of the same domain. However, since it is unknown which two tasks may be affected, the task-centric approach assumes that every task τk of the same domain is affected by all the VCPU-stop events of VPi (and thus includes all of the corresponding overheads in the inflated WCET of the task). While this approach is safe, it is very conservative, especially when the number of tasks or the number of events is high.
EVALUATION
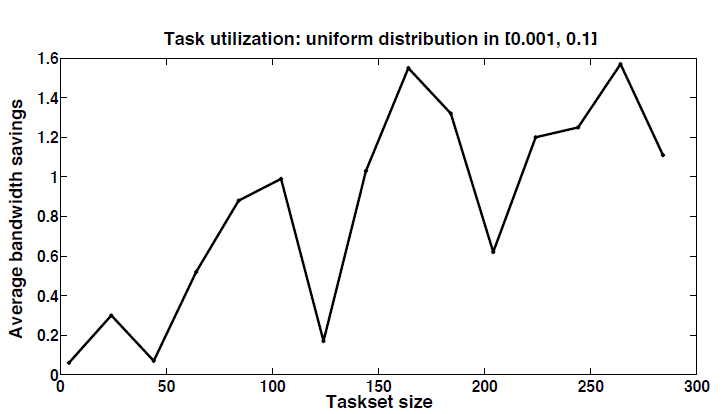
Fig. 8: Savings per taskset size.

Fig. 9: Average resource bandwidth saved with different task utilization.
Figure 8 shows the average resource bandwidth savings of the hybrid approach compared to the task-centric approach for the uniform distribution. We observe that the hybrid approach almost always outperforms the task-centric approach. Fig. 9(a)–9(c) show the average resource bandwidth savings for different taskset sizes with the three bi-modal distributions.
We observe that, across all three cases, the hybrid approach consistently outperforms the task-centric approach. In addition, as the number of tasks increases, the savings also increase. This is expected because the task-centric technique inflates the WCET of every task with all the cache-related overhead each task experiences; hence, its total cache overhead increases with the size of the taskset.
RELATED WORK
Several compositional analysis techniques for multicore platforms have been developed but, unlike this work, they do not consider the platform overhead. There are also methods that account for cache-related overhead in multicore schedulability analysis, but they cannot be applied to the virtualization and compositional setting. To the best of our knowledge, the only existing overhead-aware interface analysis is for uniprocessors.
CONCLUSION
We have presented a cache-aware compositional analysis technique for real-time virtualization multicore systems. Our technique accounts for the cache overhead in the component interfaces, and thus enables a safe application of the analysis theories in practice. We have developed two different approaches, model-centric and task-centric, for analyzing the cache-related overhead and for testing the schedulability of components in the presence of cache overhead.
We have also introduced a deterministic extension of the MPR model, which improves the interface resource efficiency, as well as accompanying overhead-aware interface computation methods. Our evaluation on synthetic workloads shows that our interface model can help reduce resource bandwidth by a significant factor compared to the MPR model, and that the model-centric approach achieves significant resource savings compared to the task-centric approach (which is based on WCET inflation).
Source: University of Pennsylvania
Authors: Meng Xu | Linh T.X. Phan | Insup Lee | Oleg Sokolsky | Sisu Xi | Chenyang Lu | Christopher Gill