
ABSTRACT
Credit Decisions are extremely vital for any type of financial institution because it can stimulate huge financial losses generated from defaulters. A number of banks use judgmental decisions, means credit analysts go through every application separately and other banks use credit scoring system or combination of both. Credit scoring system uses many types of statistical models. But recently, professionals started looking for alternative algorithms that can provide better accuracy regarding classification.
Neural network can be a suitable alternative. It is apparent from the classification outcomes of this study that neural network gives slightly better results than discriminant analysis and logistic regression. It should be noted that it is not possible to draw a general conclusion that neural network holds better predictive ability than logistic regression and discriminant analysis, because this study covers only one dataset. Moreover, it is comprehensible that a “Bad Accepted” generates much higher costs than a “Good Rejected” and neural network acquires less amount of “Bad Accepted” than discriminant analysis and logistic regression.
So, neural network achieves less cost of misclassification for the dataset used in this study. Furthermore, in the final section of this study, an optimization algorithm (Genetic Algorithm) is proposed in order to obtain better classification accuracy through the configurations of the neural network architecture. On the contrary, it is vital to note that the success of any predictive model largely depends on the predictor variables that are selected to use as the model inputs. But it is important to consider some points regarding predictor variables selection, for example, some specific variables are prohibited in some countries, variables all together should provide the highest predictive strength and variables may be judged through statistical analysis etc. This study also covers those concepts about input variables selection standards.
STUDY DESIGN
Research Objective
The objective of the thesis is to classify and compare the predictive accuracy of the artificial neural network algorithm with the traditional and widely used statistical models. Moreover, it will provide the concepts and theories that should be reviewed and considered during the selection of the predictor variables for the development of any type of credit scoring system.
LITERATURE REVIEW ON CREDIT SCORING
Risk is everywhere. May be, risk components have been increased dramatically in the recent years in comparison with the past, especially in the case of health and safety issues, it is also true in the case of financial products, for example, credit risk (Culp 2001). And this credit risk develops from the probability that the borrowers may be unwilling or unable to fulfill their contractual obligations (Jorion 2000).
The most important tool for the assessment of credit risk is credit scoring and credit scoring attempts to summarize a borrower’s credit history by using credit scoring model (Fabozzi, Davis et al. 2006). Credit scoring models are decision support systems that take a set of predictor variables as input and provide a score as output and creditors use these models to justify who will get credit and who will not (Jentzsch 2007).
LITERATURE REVIEW ON PREDICTOR VARIABLES SELECTION
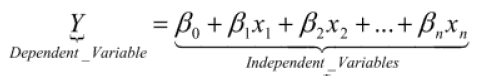
Figure 1: Credit Scoring Model Structure (Jentzsch 2007).
Credit scoring is performed through “Credit Risk Assessment”. And the credit risk assessment has mainly three purposes (Colquitt 2007). First of all and most importantly, it goes through the borrower’s probability of repaying the debt by appraising his income, character, capacity and capital adequacy etc. In addition, it attempts to identify borrower’s primary source of repayment, especially in the case of extended debt. And finally, it tries to evaluate borrower’s secondary source of repayment if the primary source of repayment becomes unavailable.
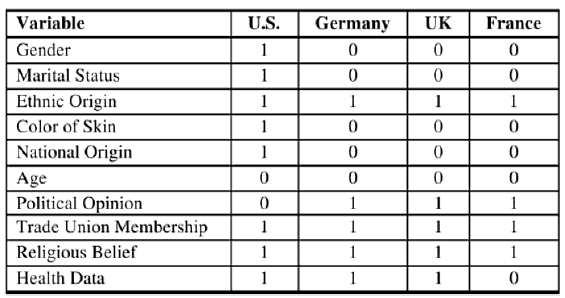
Table 2: Prohibited variables in the countries (Jentzsch 2007).
The study of Jentzsch (2007) reviews some important considerations regarding the selection of the explanatory variables. The author briefs that commercial models possess 30 variables on an average and those models are good at estimating the probability of debt repayment. Additionally, some specific variables are prohibited in some countries, as presented in the table 2.
DATA COLLECTION AND PREPARATION
Data Collection
A real world credit card dataset is used in this study. The dataset is extracted from the UCI Machine Learning Repository1 (http://archive.ics.uci.edu/ml/). The name of the Financial Institution is ignored in the repository for protecting the sensitive customer data. The dataset is referred as “German Credit Dataset” in the database. After preparing or cleaning the dataset, it is used in the subsequent sections for conducting the analysis with Logistic Regression, Discriminant Analysis, and Neural Network. Data description is given in next.
PREDICTIVE MODELS DEVELOPMENT
Discriminant Analysis
Discriminant analysis is a statistical technique to classify the target population (in this study, credit card applicants) into the specific categories or groups (here, either creditworthy applicant or non-creditworthy applicant) based on the certain attributes (predictor variables or independent variables) (Plewa and Friedlob 1995). Discriminant analysis requires fulfilling definite assumptions, for example, assumption of normality, assumption of linearity, assumption of homoscedasticity, absence of multicollinearity and outlier, but this method is fairly robust to the violation of these assumptions (Meyers, Gamst et al. 2005).
Here, in this study, it is assumed that all required assumptions are fulfilled to use the predictive power of the discriminant analysis for classification of the applicants. At this point, “creditworthiness” is the dependent variable (or, grouping variable) and the rest 20 variables are the independent variables (or, input variables). Here, the output of the discriminant analysis is reported below.
COMPARISON OF THE MODEL’S PREDICTIVE ABILITY
Discriminant Analysis
In the discriminant analysis model development phase, a statistically significant model is derived which possess a very good classification accuracy capability. In the following table, it is shown that the discriminant model is able to classify 621 good applicants as “Good Group” out of 700 good applicants.
Thus, it holds 88.7% classification accuracy for the good group. On the other hand, the same discriminant model is able to classify 143 bad applicants as “Bad Group” out of 300 bad applicants. Thus, it holds 47.67% classification accuracy for the bad group. Thus, the model is able to generate 76.4% classification accuracy in combined groups.
OPTIMIZATION OF NEURAL NETWORK PERFORMANCE & FUTURE RESEARCH SCOPE
There are two main issues about the performance of the neural network. First of all, it is important to determine its structure and secondly, it is also vital to specify the weights of the neural network that help to minimize the total errors (Deb, Poli et al. 2004). These are optimization issues. Evolutionary algorithm (genetic algorithm) is a kind of optimization technique that uses selection and recombination as the main instruments to deal with optimization problems (Kamruzzaman, Begg et al. 2009).For example, genetic algorithm is the main available method that can be used to find well suited network architecture for a given task or problem (Patel, Honavar et al. 2001).
According to the genetic algorithm theory, all combinations of the parameters of the possible solutions of a given problem (in this analysis, all the possible combinations of the parameters of the neural network architecture) must be coded into a gene and by a process of the selection of the fittest (in this case, the best neural network architecture that provides better classification) only the best solutions are selected for the reproduction, and after each subsequent generation, new solutions (only selected if they provide better classification accuracy) are generated by means of the reproduction between solutions and their related mutations (Mira, Cabestany et al. 2009).
MANAGERIAL IMPLICATIONS
Credit scoring models are decision support systems that help managers to assess a potential customer to accept or reject his application. But it requires careful considerations to develop and use these types of decision support systems. Anderson (2007) reviews some important factors regarding the practical development and implementation of the credit scoring systems. The following is a review of author’s suggestions, summarized with the views of this study.
FINDINGS AND CONCLUSION
Appropriate predictor variables selection is one of the conditions for successful credit scoring models development. This study reviews several considerations regarding the selection of the predictor variables. Moreover, using the Multilayer Perceptron Algorithm of Neural Network, network architecture is constructed for predicting the probability that a given customer will default on a loan. The model results are comparable to those obtained using commonly used techniques like Logistic Regression or Discriminant Analysis, as described in the following.
There are two noteworthy and interesting points about this table. First of all, it shows the predictive ability of each model. Here, the column 2 and 5 (“Good Accepted” and “Bad Rejected”) are the applicants that are classified correctly. Moreover, the column 3 and 4 (“Good Rejected” and “Bad Accepted”) are the applicants that are classified incorrectly. Furthermore, it shows that neural network gives slightly better results than discriminant analysis and logistic regression.
It should be noted that it is not possible to draw a general conclusion that neural network holds better predictive ability than logistic regression and discriminant analysis, because this study covers only one dataset. On the other hand, statistical models can be used to further explore the nature of the relationship between the dependent and each independent variable, and statistical models are preferred than neural network if there is tiny difference in predictive ability of the neural network and the statistical models.
Source: Blekinge Institute of Technology
Authors: Md. Samsul Islam | Lin Zhou | Fei Li